
The Pirate’s Guide to AI Image Prompting
How to Make AI Pictures That Don’t Suck


Ahoy again. Portavoz Pirata here, back with another guide for you AI-obsessed scallywags. Last time we talked about wrangling text from robots. Today, we’re drawing PICTURES with them.
Remember when “AI art” meant those fever-nightmare dog pictures from DeepDream? Boy howdy, we’ve come a long way. Today’s models can create realistic photos, anime waifus, corporate logos, and everything in between, all in an instant. The catch? Most people’s AI art still looks like hot garbage because they don’t know how to talk to these visual models.
This is because people don’t seem to realize that prompting an image AI is kinda like playing reverse Pictionary with a very talented but extremely literal artist who’s also possibly high.
Well, no more! I’ve come to right this ship, once and for all. You see, I’ve generated approximately 47,000 images (yes, I counted) between every major imaging model, burning through more GPU hours than a crypto mining farm. Along the way, I learned a bunch of tricks to make these models sing (well, technically “paint,” but this is my article so screw you, and that’s final). So settle in, grab your rum and let me show you how to make AI pics that don’t immediately scream “I WAS MADE BY A ROBOT.”

What the Hell is Image Prompting?
Image prompting, like text prompting, is the fine art and mad science of convincing an AI to draw what’s actually in your head instead of what it thinks you meant.
These models (their technical moniker is “diffusion models”) work by starting with pure noise and gradually “denoising” it into an image based on your text prompt. The prompt guides this process, telling the model which patterns to enhance and which to suppress. Get it wrong, and you get a six-fingered monstrosity. But get it right, and people will swear you hired a professional artist.
Sound familiar? Good. Because it’s a similar deal to what we’ve already been through with prompting LLMs.
However, image prompting differs from text prompting in one critical way: visual models are simultaneously more forgiving and more punishing than LLMs. They’ll give you something no matter how bad your prompt is, but that “something” might haunt your nightmares worse than a yiff furry’s banned DeviantArt profile.
Know Your Models (They’re All Weird in Different Ways) – [Image AI Edition]
So, you might have already heard a bunch of different names bandied about: Midjourney, DALL-E, Stable Diffusion, et al. These are the most-used image models, and just like with LLMs, each of these AIs has its own quirks, oddities, pain points, and best practices. We’ll go over each in more detail, but if you need a quick reference, just save this handy-dandy chart:
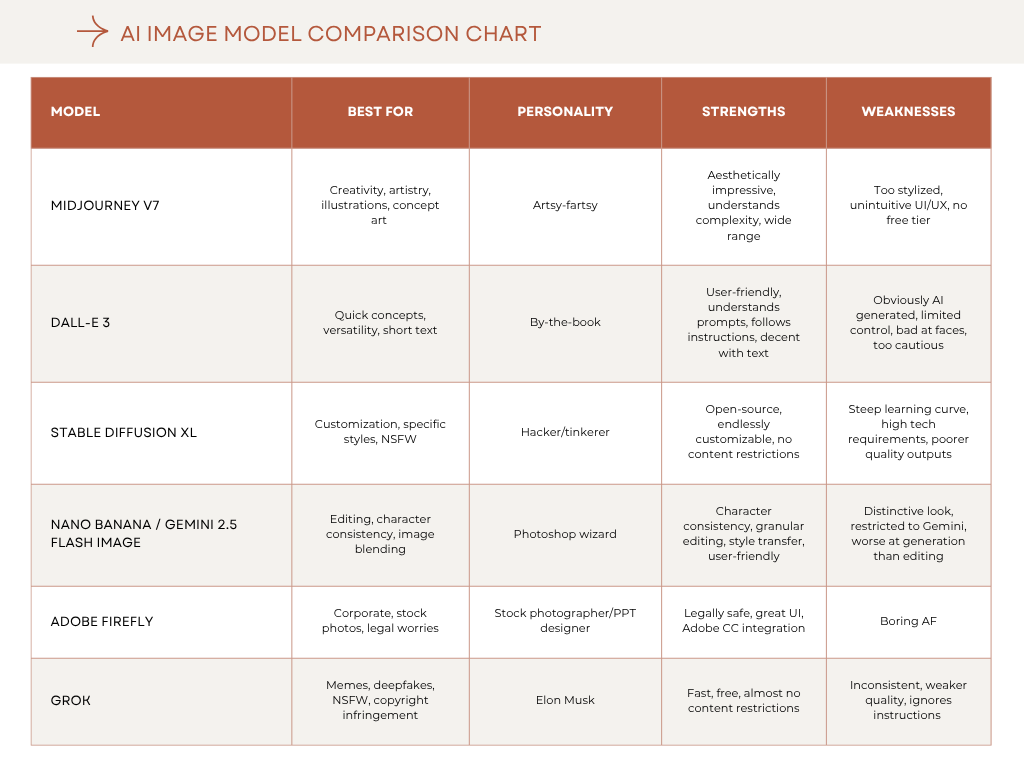
Midjourney (The Overachiever)

Personality: The art school graduate who actually got a job
Midjourney is the current king of “looks good out of the box.” Even your garbage prompts will produce something stunning, or at least aesthetically pleasing. It has a distinctive style: kind of dreamy, slightly oversaturated, and very “artistic.” Version 7 (released April 2025, default since June) finally perfected natural language understanding and added some real game-changing features.
The Good:
Consistently beautiful results
Draft Mode: 10x faster, half cost for rapid iteration
V7 understands complex scene descriptions perfectly
Omni Reference for consistent characters/objects
Amazing at lighting, atmosphere, and textures
Personalization on by default (learns your preferred style)
The Bad:
That distinctive “Midjourney look” is hard to shake
Costs money (no free tier anymore)
Discord-only interface is annoying as hell (and the web UI isn’t much better)
Can’t do NSFW content (and I mean anything - it once blocked me for “sensual fruit”)
Sometimes too artistic when you want realism
Best for: Editorial illustrations, concept art, rapid prototyping with Draft Mode, anything that needs to look immediately impressive
Pro Tip: Use --style raw to reduce the Midjourney sauce and get more literal interpretations. Use --draft for quick iterations, then enhance your favorites.
DALL-E 3 (The Teacher’s Pet)

Personality: The straight-A student who follows all the rules
DALL-E 3 is integrated with ChatGPT (now using GPT-5) and automatically enhances your prompts using GPT’s language model. This is both a blessing and a curse: it’ll turn your caveman grunts into Shakespeare, but sometimes you want caveman grunts.
The Good:
Integrated with ChatGPT/GPT-5 (convenience is king)
Actually somewhat competent at generating text in images (keep it to 1-2 words though)
Excellent prompt understanding via GPT-5
Good at following specific instructions
Free tier available with ChatGPT
The Bad:
That oversaturated, plastic DALL-E look
Terrible at human faces (they look like bad plastic surgery)
Overzealous safety filters
Limited control compared to open-source options
Can’t iterate on specific images easily
Best for: Quick concepts, when you need text in images, edumacational content (ie, visuals for slides and infographics and shit)
Pro Tip: Tell it explicitly to “make it look like a human artist did it” to reduce the AI smoothness. Start prompts with “Generate exactly as written, do not modify:” for precise control.
Stable Diffusion XL (The Swiss Army Knife)

Personality: The open-source hacker who builds his own everything
SDXL is for when you want complete control. This is the Linux of image generation: infinitely customizable, often frustrating, and beloved by people who say things like “I compiled it from source.”
The Good:
Completely free and open source
Runs locally (your weird shit stays private)
Thousands of fine-tuned models available
LoRA support for infinite customization
Can generate literally anything (no content filters)
The Bad:
Very steep learning curve
Needs reams of negative prompts to not look like ass
Requires decent hardware or cloud compute
Default output often needs work
Hands still occasionally have extras fingers (though much improved)
Best for: When you need specific styles, NSFW content, complete control, or bulk generation
Pro Tip: Use checkpoint models (like RealVisXL for photorealism) for specific artistic styles. Always include comprehensive negative prompts.
Google’s “Nano Banana” / Gemini 2.5 Flash Image (The Editing Wizard)

Personality: The post-production specialist who named themselves after a fruit for the lulz
Holy shit, Google actually named their model “Nano Banana.” I’m not making this up. They’ve since tried to walk it back and call it “Gemini 2.5 Flash Image” but the internet never forgets. This model went viral on LMArena under its banana alias before Google sheepishly admitted it was theirs.
But bonkers name aside, this model is insanely good at image editing. Not just generation from scratch… but actual image editing. BRUH. It’s like having a Photoshop wizard on crack.
The Good:
Best-in-class character consistency (your face stays your face)
Can blend multiple images seamlessly
Multi-turn editing (keep refining the same image)
Style transfer that actually works
Free tier gets you 100 edits/day
Integrated into Gemini app
$0.039 per image via API (cheap!)
The Bad:
More editor than generator (needs existing images to truly shine)
Still has that slightly “Google-y” look
The name. I mean, come on. Nano Banana?
Limited to Gemini ecosystem
Sometimes goes too bananas with edits (pun abso-fucking-lutely intended)
Best for: Editing existing photos, character consistency across multiple images, “what would I look like as a pirate” scenarios
Pro Tip: Upload multiple reference images and let it blend them. This thing is magic at maintaining likeness while changing everything else.
Fun Nano Banana Prompt: “Take this photo of me and make me look like a Victorian gentleman, but keep my face exactly the same, standing in a steampunk laboratory”
Adobe Firefly (The Corporate Safe Choice)

Personality: The HR-approved designer who went to all the gay sensitivity trainings
Firefly was trained exclusively on Adobe Stock images, which means it’s legally bulletproof but also kind of... boring (yet also vaguely gross in the way only truly boring shit can be). If mayo was an AI image generator, it’d be Firefly.
The Good:
Commercially safe for business use
Integrated into Creative Cloud
Great UI with helpful sidebars
Good for product mockups
Excellent for generic stock photos
The Bad:
Doesn’t know any artist names (by design)
Generally produces safe, boring images
Limited artistic range
Requires Creative Cloud subscription for full features
Best for: Corporate work, stock photography, when legal wants to review everything
Grok (The Chaotic Edgelord)




Personality: The one who got expelled for drawing dicks on everything
Grok uses the Aurora model and is integrated directly into X/Twitter. It has fewer restrictions than most other models (like, WAY fewer) and can even generate images of public figures and copyrighted characters. Use this power responsibly (or don’t, I’m not your dad).
The Good:
Fast as hell
Minimal content restrictions
Free tier available on X
Surprisingly decent at photorealism
Can actually generate celebrities and copyrighted stuff
The Bad:
Wildly inconsistent quality
Sometimes straight up ignores parts of your prompt
That edgelord energy attracts likeminded users (warning: you can’t un-see some of this shit)
Limited customization options
Best for: Memes, deepfakes,1 copyright infringement, when other models are being too schoolmarm-ish, quick iterations
The Anatomy of a Perfect Prompt

Unlike my text prompting guide where I basically told you to just be verbose as fuck, image prompting needs more structure. So on that note, here’s the formula that actually works:
[Medium/Style] + [Subject with details] + [Environment/Background] + [Lighting/Mood] + [Technical specifications] + [Artist style (if applicable)]
Breaking It Down:
Medium/Style: Start by telling it what kind of image you want.
“Oil painting of...”
“Professional photograph of...”
“3D render of...”
“Pencil sketch of...”
Subject Details: Be autistically specific about your main subject.
Don’t say “woman”; say “young woman with long auburn hair, green eyes, wearing a vintage 1950s polka dot dress”
Don’t say “dog”; say “golden retriever puppy with floppy ears playing with a red ball”
Environment: Context matters!
“in a misty forest at dawn”
“modern minimalist apartment with floor-to-ceiling windows”
“cyberpunk alley with neon signs reflecting in puddles”
Lighting/Mood: This is what separates the bad from the good, and the good from the amazeballs.
“dramatic rim lighting”
“soft golden hour sunlight”
“moody film noir shadows”
“flat overcast lighting”
Technical Specs: Camera/artistic techniques are often neglected, but highly elevate the image’s believability.
“shot with 85mm lens, shallow depth of field”
“wide angle perspective”
“tilt-shift photography”
“double exposure”
Examples That Actually Work
Portrait Photography

❌ Bad: “Pretty woman”

✅ Good: “Professional portrait photograph of an elegant woman in her 30s with short black hair and striking amber eyes, wearing a emerald green silk blouse, sitting in a mid-century modern chair against a cream colored wall, soft window light from the left creating subtle shadows, shot with 85mm lens at f/2.8, shallow depth of field, in the style of Annie Leibovitz”
Fantasy Illustration

❌ Bad: “Dragon”

✅ Good: “Digital painting of an ancient crimson dragon perched on a mountaintop fortress ruins, scales gleaming with an iridescent sheen, storm clouds gathering behind, lightning illuminating its spread wings, treasure scattered at its feet, dramatic lighting from below, epic fantasy art style, highly detailed, in the style of Michael Whelan”
Product Design

❌ Bad: “Cool sneaker design”

✅ Good: “Futuristic running shoe design, white mesh upper with holographic accents, transparent air-cushion sole with visible orange gel pods, carbon fiber heel counter, floating product photography against gradient background, studio lighting, 3D render, octane render, product visualization”
Common Fuck-Ups and How to Fix Them
The Hand Problem

AI struggles with hands because they’re small, highly variable, and often partially obscured in training data.